本篇目录:
- 1、客户端怎么使用ceph的块设备
- 2、如何基于Ceph打造一款高可靠的块存储系统
- 3、ceph的对象存储兼容的接口类型是
- 4、Ceph高可用部署和主要组件介绍
- 5、ceph客户端需要以下哪些数据才能与ceph集群进行通信
- 6、ceph如果某一个节点主机挂了,数据是否会丢失,是否还能容错?
客户端怎么使用ceph的块设备
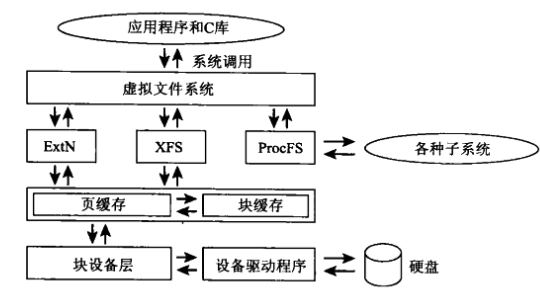
1、块设备接口:这是 Ceph 的默认接口,提供类似于传统块设备的使用方式。用户可以使用块设备接口像访问本地存储一样访问 Ceph 对象存储。网络文件系统接口:Ceph 的网络文件系统接口允许用户像使用传统文件系统一样使用对象存储。
2、除了 cinder-volume 之后,Cinder 的 Backup 服务也可以对接 Ceph,将备份的 Image 以对象或块设备的形式上传到 Ceph 集群。
-图1")
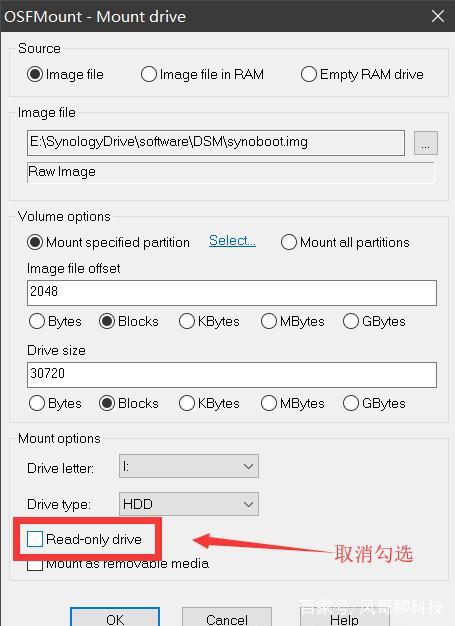
3、首先添加一块高性能硬盘(我这里是虚拟环境,只能用普通硬盘充数)然后需要利用 crush 让不同池使用不同的存储设备 这里只能拿普通的虚拟硬盘来做测试。在 ceph02 虚拟机上增加一块 30G 的虚拟硬盘。
4、Ceph配置文件:客户端需要读取Ceph配置文件以获取集群的详细配置信息。该配置文件被命名为ceph.conf,其中包含了各个组件的配置项,如Monitor地址、存储池信息等。
如何基于Ceph打造一款高可靠的块存储系统
1、在ceph-1节点为Ceph文件系统创建数据和元数据存储池。
-图2")
2、Ceph是根据加州大学Santa Cruz分校的Sage Weil的博士论文所设计开发的新一代自由软件分布式文件系统,其设计目标是良好的可扩展性(PB级别以上)、高性能及高可靠性。
3、首先,在对象存储中,一切都是扁平化的,并且存储的最小单元为对象(obj)。存储 obj 如下图:ceph 在对象存储的基础上提供了更加高级的思想。当对象数量达到了百万级以上,原生的对象存储在索引对象时消耗的性能非常大。
4、Ceph对象存储只有在特定环境中才能够发挥最佳性能表现。这款产品在研发过程中考虑到云环境相关需求,且价格适中,能够轻松扩展成PB级存储。但是部署Ceph并不简单,IT员工必须对产品进行充分了解。
-图3")
5、使用 ceph-deploy 工具部署 ceph 存储集群。使用虚拟机构建三节点 ceph 存储集群。全篇使用 root 权限。
6、CephMgr :在一个主机上的守护进程,负责运行指标,运行状态,性能负载, 其他术语: RADOS:多个主机组成的存储集群,即可靠,自动化,分布式的对象存储系统。
ceph的对象存储兼容的接口类型是
块存储(Block Storage),作为块设备像硬盘一样直接挂载。 文件系统(File System) ,如同网络文件系统一样挂载,兼容POSIX接口。
Ceph是分布式文件存储系统,里面提供了对象存储,块存储和文件系统,这个文件系统也就是CephFS。所以Ceph包括了CephFS。
对象存储: 也就是通常意义的键值存储,其接口就是简单的GET,PUT,DEL和其他扩展,如七牛、又拍,Swift,S3等。
Ceph高可用部署和主要组件介绍
vim /opt/ceph-deploy/ceph.conf 在 global 中增加:当前命令执行以后,可以在当前目录下发现许多的 keyring 文件,这是连接其它节点的凭据。以后的 ceph-deploy 命令均在当前目录下执行才可正常使用。
多数派机制:ceph分布式存储系统是依赖monitor管理ceph集群中的各种视图,如OSD视图与MDS视图。而monitor服务本身也是基于paxos算法的分布式集群。
高可用:在Ceph Storage中,所有存储的数据会自动从一个节点复制到多个其他的节点。这意味着,任意节点中的数据集被破坏或被意外删除,在其他节点上都有超过两个以上副本可用,保证您的数据具有很高的可用性。
主要由API Server(kube-apiserver)、Control Manager(kube-controller-manager)和Scheduler(kube-scheduler)这3个组件。以及一个用于集群状态存储的etcd存储服务组成。kube-apiserver API Server是 Kubernetes控制平台的前端。
超融合架构的主要组件有:分布式存储系统、高速网络、统一管理平台。
Ceph:一种分布式存储系统,可以提供高性能、高可靠性和高可扩展性的数据存储服务。3GlusterFS:一种分布式文件系统,可以处理大规模文件和数据存储需求。
ceph客户端需要以下哪些数据才能与ceph集群进行通信
1、数据实际存储在ceph集群中。利用librados的接口,与ceph集群通信。RGW主要存储三类数据:元数据(metadata)、索引数据(bucket index)、数据(data)。这三类数据一般存储在不同的pool中,元数据也分多种元数据,存在不同的ceph pool中。
2、网络文件系统接口:Ceph 的网络文件系统接口允许用户像使用传统文件系统一样使用对象存储。用户可以使用网络文件系统接口在客户端和 Ceph 对象存储之间传输数据。
3、因此, Ceph可以分两次向客户端进行确认。当各个OSD都将数据写入内存缓冲区后,就先向客户端发送一次确认,此时客户端即可以向下执行。待各个OSD都将数据写入磁盘后,会向客户端发送一个最终确认信号,此时客户端可以根据需要删除本地数据。
4、Openstack中需要进行数据存储的三大项目主要是nova项目(虚拟机镜像文件),glance项目(共用模版镜像)与cinder项目(块存储)。
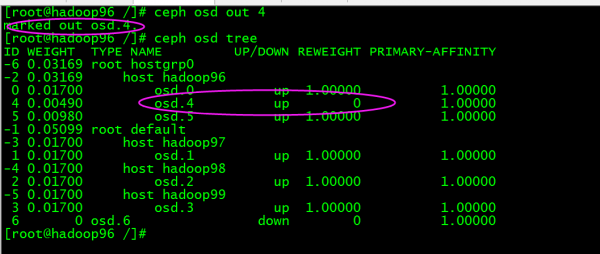
5、ceph 集群详细状态:ceph -s ceph 集群 osd 状态:ceph osd tree 至此,该集群还处于一个基础的状态,并不能正常使用。接下来需要配置 ceph pool 相关信息,以及安装配置 rgw 从而使用对象存储功能。
ceph如果某一个节点主机挂了,数据是否会丢失,是否还能容错?
除了Ceph守护进程之外,你还必须考虑主机是否会运行CPU密集型进程,例如,如果您的主机将运行计算虚拟机(例如,OpenStack Nova),您需要确保这些其他进程为Ceph守护进程留下足够的处理能力。我们建议在单独的主机上运行额外的CPU密集型进程。
如果想使 PG 5 重新上线,例如,上面的输出告诉我们它最后由 osd.0 和 osd.2 管理,重启这些 ceph-osd 将恢复之(可以假定还有其它的很多 PG 也会进行恢复 )。
这样可以提高数据的可靠性和可用性,即使某个节点发生故障,数据仍然可以从其他节点中恢复。
而在异步系统中,主机之间可能出现故障,因此需要在默认不可靠的异步网络中定义容错协议,以确保各个主机达到安全可靠的状态共识。 共识算法其实就是一组规则,设置一组条件,筛选出具有代表性的节点。
到此,以上就是小编对于cephvolume的问题就介绍到这了,希望介绍的几点解答对大家有用,有任何问题和不懂的,欢迎各位老师在评论区讨论,给我留言。
 微信扫一扫打赏
微信扫一扫打赏